En el post de hoy hablaremos del protocolo PRP de redundancia para redes Ethernet de tipo industrial y en el siguiente post hablaremos del protocolo HSR también para redundancia pero en esta ocasión en anillo.
¿Qué es PRP y cómo funciona?
En pocas palabras, PRP se basa en que cada equipo conectado a la red PRP transmite la información por dos redes en paralelo totalmente independientes. Para ello el nodo necesita dos interfaces de red, una conectada a cada una de las redes. En recepción, el nodo destino del paquete recibirá el mismo por ambas interfaces, tomando el primer paquete que le llegue y descartando el segundo (duplicado)
PRP es un protocolo con dos claras ventajas y un claro inconveniente. Las ventajas son:
- no necesitamos ninguna redundancia o protección en cada una de las redes, es decir, no necesitamos topologías en anillo o similares ya que la redundancia en sí se consigue por el hecho de duplicar las redes. Esto significa que podemos usar switches u otros dispositivos económicos (incluso no gestionables si no hemos de usar vlans)
- es un protocolo de los llamados ZPL (Zero Packet Loss), es decir, en caso de caída de una de las redes, no perdemos ni un solo paquete ya que éstos siempre van duplicados. Ningún protocolo en anillo por rápido que sea su tiempo de recuperación es ZPL ya que siempre se perderá algún paquete entre el tiempo de caída del anillo y la conmutación de caminos para su recuperación
Por el contrario, el inconveniente es también claro: necesitamos duplicar la infraestructura de red ya que tendremos siempre dos redes independientes en paralelo. Eso sí, como ya hemos dicho, estas redes no necesitan protecciones adicionales.
En el diagrama siguiente vemos un esquema de una típica red PRP en la que conectamos dos tipos de dispositivos: SAN o Single Attach Networks, son aquellos nodos que sólo tienen un interfaz de red y que por tanto no pueden conectarse directamente a una red PRP en paralelo y los DANP o Dual Attach Network in Parallel que sí tienen dos interfaces de red con funcionamiento PRP y por tanto pueden conectarse directamente a ambas redes (A y B).

En el primer caso de los SAN, necesitamos un dispositivo intermedio normalmente llamado RedBox que nos permita duplicar el tráfico recibido del SAN hacia dos puertos en paralelo hacia la red PRP.
 ¿Cómo funciona internamente un dispositivo PRP?
¿Cómo funciona internamente un dispositivo PRP?
Si hacemos un zoom a un dispositivo con capacidades PRP podemos ver que es algo bastante más complicado que un nodo de red con con interfaces de red.
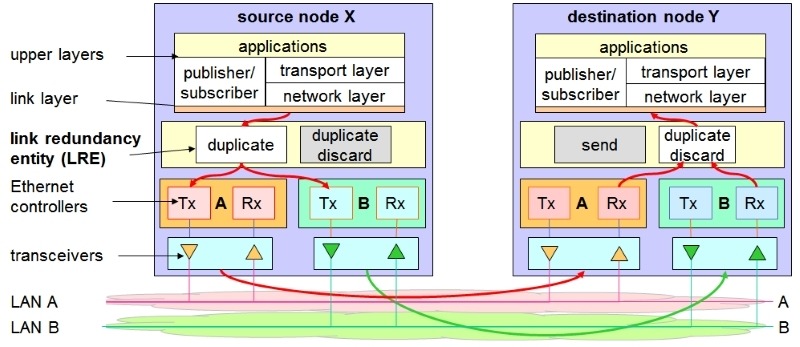
Como podemos ver la implementación del protocolo PRP residen entre los controladores Ethernet y el llamado Link Redundancy Entity. Básicamente estos niveles deben encargarse en la transmisión de un paquete de duplicarlo entre ambos interfaces físicos y en la recepción de dicho paquete en recibir el primero de ellos y descartar el duplicado.
La idea de hacer recaer todo este proceso en los niveles inferiores del stack de protocolos es poder liberar al procesador del nodo de estas tareas y al mismo tiempo independizar el tratamiento de los paquetes Ethernet del hecho de que la red sea o no PRP.
¿Cómo descartar los duplicados de las tramas?
Para llevar a cabo las funciones anteriormente descritas, PRP añade una serie de campos específicos al formato de trama Ethernet estándar.

Como vemos este PRP tráiler está formado por:
- un número de secuencia de 16 bits
- un identificador de LAN de 4 bits (1010 (0x0A) para la LAN_A y 1011 (0x0B) para la LAN-B)
- un indicador de longitud de 12 bits (cuenta la longitud del payload de la trama excluyendo los bytes de tags de vlans y el PRP tráiler)
- un sufijo PRP (opcional) en caso de tramas cortas donde necesitemos un relleno
En transmisión el nodo PRP incrementa el número de secuencia con cada paquete (este número de secuencia es individual para cada dirección MAC destino) y añade el identificador de LAN a cada una de las redes. Por último añade el identificador de longitud de trama PRP.
En recepción el número de secuencia nos permite detectar duplicados o cambios de orden de paquetes e identificar perfectamente los mismos. Asimismo, el identificador de longitud nos permite distinguir de forma rápida las tramas PRP de las que no son PRP y que puedan llegar por el mismo interfaz de red.
Cuando se empieza a recibir un paquete por una de las redes se abre una ventana de tiempo de disponibilidad en la otra red durante la cual estamos recibiendo y procesando el paquete. Tan pronto detectemos que el paquete es correcto se cierra dicha ventana de disponibilidad y descartamos el paquete que pudiéramos estar recibiendo por la segunda red. Si por el contrario el primer paquete es erróneo, lo descartaremos y pasaremos a tomar el segundo paquete.
Supervisión en redes PRP
Para su correcto funcionamiento, una red PRP necesita que todos sus nodos tengan un cierto control y supervisión de la situación de dicha red. Por ejemplo: necesitan unas tablas comunes con los números de secuencia de los paquetes que les permitan detectar duplicados o cambios de secuencia o incluso nodos que han desaparecido de la red y dejan de enviar y recibir paquetes.
De cara a llevar todo este control, los nodos de las redes PRP y especialente las RedBox que deben llevar el control de dispositivos no PRP conectados a ellas se intercambian unos paquetes de supervisión que pueden ser tagged o untag en función de la configuración de la red de transporte que los une y en la que podemos encontrar los campos descritos en la siguiente tabla.

Soluciones PRP de Kyland
El fabricante Kyland dispone de dos productos con capacidades PRP
- Ruby3A – es una Redbox en formato para carril DIN con dos uplinks GX y uno o varios puertos de acceso para nodos SAN
- Módulo PRP/HSR para la gama de switches modulares GPT. Este módulo permite integrar al switch y a todos los SAN conectados a él e una red PRP o HSR dotándoles de redundancia


 - Los Miércoles de Tecnología")

")

Los comentarios están cerrados.